

The Prompt Log, No. 02
A recurring feature on building Workforce Rewired with AI, in public, in real time.


TL;DR: Every weekday morning, a briefing on AI and workforce trends lands in my inbox. I didn’t write it. I didn’t set an alarm. I built a system that runs while I sleep, pulls from primary sources, deduplicates against the last ten issues, and drafts a formatted HTML email ready for me to review and send. It’s what you see in the Daily Workforce Rewired Briefing. Every 10 days, a second agent audits the last ten issues and files a findings report I read in my next session. Here is what that actually looks like, including the most recent report.
The Thing I Promised at the End of Last Time
At the close of the first Prompt Log, I teased the daily briefing system that lands in my inbox every morning. I said there had been casualties. Multiple agents did not survive the process.
That was true. Let me tell you what I meant.
What the System Does
The Workforce Rewired Daily Briefing runs on a scheduled task. Every morning, before I’m awake, an AI agent does the following.
It reads a standing rules document I’ve built and maintained called briefing-feedback.md. This file contains everything the agent needs to know about what I want: section order, formatting rules, source quality standards, content balance requirements, and a running log of specific corrections from recent issues. The agent reads it before doing anything else. These rules override any default judgment the agent would apply.
Then it searches Gmail across both of my accounts for the last ten briefings, reads them in full, and builds a deduplication inventory. Every named source, study, company, and statistic that appeared in any of the last ten issues goes on the list. Nothing on that list appears again. The matching logic matters here: deduplication runs on source institution and publication date, not on headline. A story headlined “BCG: Half of All U.S. Jobs Will Change” and one headlined “BCG Analyzed 165 Million Jobs. Half Will Change.” are the same source -- BCG Henderson Institute, same publication date. They do not both appear.
Then it searches for news. Only stories published in the last 48 hours. Only from recognized primary sources: established outlets, government releases, original research from institutions like McKinsey, WEF, Brookings, Goldman Sachs, Stanford HAI. Aggregators and rumor sites are excluded.
Then it selects the best three to five stories, structures them into the briefing in a fixed section order, writes the “Why it matters” line for each, and drafts the whole thing as a formatted HTML email with a navy accent bar, blue section labels, and a 680-pixel max width. It saves the draft to Gmail. It does not send it.
I review it. I send it. I copy/paste that into Substack with almost no formatting needed.
That last part matters. The automation handles research, deduplication, structure, and formatting. The editorial call is still mine.
What the Briefing Looks Like
Every issue follows the same structure, in the same order, every time:
An opening paragraph synthesizing the day’s signal, not a list of headlines
By the Numbers: four to six statistics, each tied to a named story in the body
Layoffs and Company Decisions
Policy and Government
Reskilling and Education
What Workforce Leaders Are Watching: three to four forward-looking questions for HR leaders and institutional designers, not summaries of what was covered
The section order is not decorative. It builds a consistent reading experience. A subscriber who has been with the briefing for two months knows exactly where to find the policy news. The structure does not change. The agent knows this because the standing rules say so, explicitly

.
The 10-Day Review
Once a every 10 days, a separate task runs a meta-review of the last ten briefings. Not a second opinion on any single issue. A pattern audit.
The review agent pulls all ten issues, reads them in full, and checks each one against the standing rules: Did the format hold? Any em dashes? Is the closing section present? Was at least one worker-perspective story included? Did any source repeat within the window? Then it synthesizes findings across the full set: what is consistently strong, what is breaking in three or more issues, what belongs in the feedback file, and one observation that is not yet a problem but worth watching.
The output is a report I read in my next Cowork session. The agent surfaces the findings. I decide what actions to take. I update the feedback file. The system incorporates the correction on the next run.
On May 1, the most recent report ran. Here is what it found.
What the May 1 Report Actually Said
The review covered April 21 through April 30. Ten briefings. Two of them returned only snippet text from Gmail -- full-body analysis for those two was limited to the opening statement and structure. Two separate April 26 drafts were found in the archive (more on that in a moment). The report opened with this:
Quality has improved meaningfully from the early April baseline and the best briefings in this window -- April 26, April 27, April 28, April 29, and April 30 -- are genuinely strong: sharp framing, high-quality sources, substantive closing questions, and consistent worker perspective coverage. The most persistent problem is not editorial; it is mechanical.
That distinction -- not editorial, mechanical -- is the most useful framing. The writing was working. The system had bugs.
What was working: The review flagged the opening statements as the strongest consistent element across all ten issues. The April 28 opener got called out specifically:
“The single variable that predicts whether AI actually transforms someone’s work is whether their manager champions it. Not the technology. Not the training. The manager.”
The worker-perspective requirement was being met in every issue. The closing “What Workforce Leaders Are Watching” section -- which should pose forward-looking questions rather than summarize what was covered -- was present and substantive in all ten.
What was breaking: Three problems, each specific.
First, section label capitalization. Section headers were appearing in HTML as ALL CAPS -- “BY THE NUMBERS”, “LAYOFFS AND COMPANY DECISIONS” -- instead of Title Case. The CSS handles the visual styling via text-transform: uppercase, so the labels looked correct to the reader. The underlying HTML was wrong. This showed up in at least four of the ten briefings. The correction had been added to the feedback file, but the April 28 issue contained the violation on the same day the rule was documented -- meaning the rule was being written too late to catch the problem that prompted it.
Second, and more significant: source-level duplication within the window itself. The deduplication step was matching on headline rather than on underlying source. The same reports were getting through under different framings. From the report:
Confirmed instances:
BCG 165 million jobs / 50-55% transformation finding: Full story in April 16; full story again in April 27, reframed under a different headline. Same BCG Henderson Institute report, April 8, 2026.
Stanford AI Index / 20% early-career employment decline: Full story in April 13; full story again in April 28. Same Stanford HAI publication.
Gallup 23,717-worker survey: Full story in April 13; full story again in April 28. Same Gallup publication.
DOL $243M apprenticeship initiative: Full story in April 19 and April 20. The same underlying data reappears in the April 30 “By the Numbers” section and the Reskilling story. Three appearances of the same source across the window.
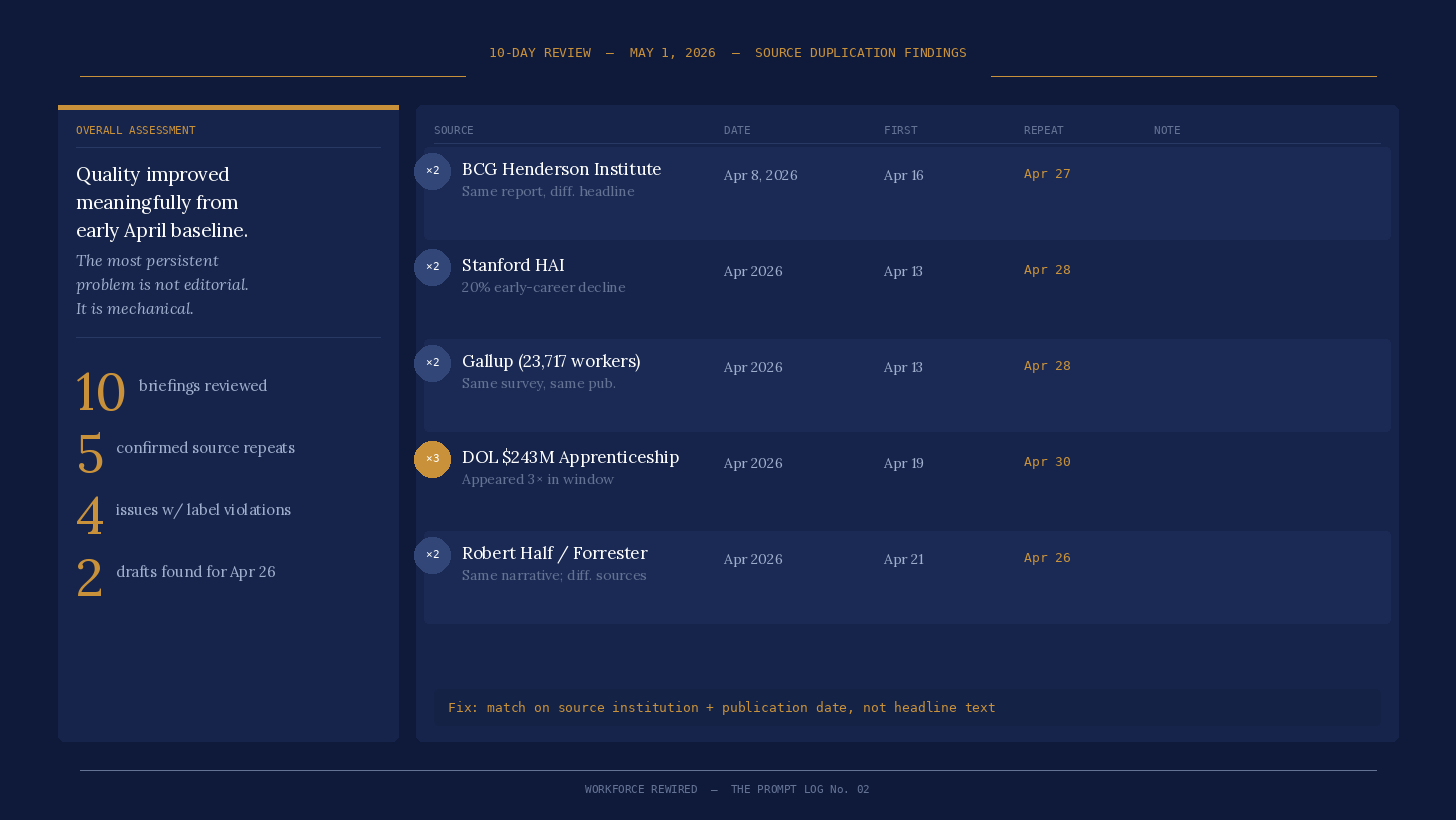
Five confirmed source-level repeats in ten issues. The fix is already in the skill update: deduplication now matches on source institution and publication date, not on headline.
Third, two separate April 26 drafts existed in the archive. One covered the CFO productivity paradox. The other covered AI rehire regret data and Connecticut’s SB 5. Both were complete, formatted briefings addressed to my Gmail. Neither was clearly marked as canonical. The deduplication inventory could read either one depending on which it found first, meaning stories from whichever draft it missed were at risk of reappearing as apparently fresh content.
The One Thing to Consider
Every review closes with a single observation that is not an urgent problem but worth the editor’s attention. The May 1 version closed with this:
The April 30 briefing closes with a question that no prior briefing has asked quite this directly: if productivity is rising, entry-level access is narrowing, worker trust is falling, and institutional investment in training remains thin -- who actually benefits from the AI transition, and how intentional is that distribution? That framing is more pointed than the briefing’s usual posture. It is also more interesting. The briefings have been strong at describing what is happening. The ones that ask explicitly who benefits, who bears the cost, and whether that is by design are the ones that would be worth reprinting in a Substack essay or citing in a speaking context. That angle is worth developing more deliberately -- not every issue, but as a recurring thread when the data supports it.
That observation is now on my list to explore more.
What I Do and What the System Does
People always ask who’s doing the work. Here is the honest division:
Automated: Research and source discovery. Deduplication against the last ten issues. Story selection and structure. “Why it matters” line drafting. HTML formatting and template compliance. Gmail draft creation. Scheduled morning delivery. Regular pattern audit across ten briefings. Findings report filed to my folder.
Requires my action: Reading the briefing before it goes out. Making the editorial call on whether to send it, hold it, or revise it. Reading the recurrent review and deciding what the findings mean. Updating the feedback file. Applying pending skill updates when new patterns are caught. Deciding whether the “who benefits” observation becomes a deliberate editorial thread.
The agent does not have editorial judgment. It has editorial rules. The rules come from me. The judgment of whether the rules are working is mine. This has been a very iterative process to produce a product that I’m genuinely happy with.
What I Actually Learned Building This
The thing nobody tells you about building an automated system is that the first version will be wrong in ways you cannot predict until it runs in production.
I did not know the deduplication would match on headline rather than source until the BCG report showed up twice in eleven days under different framings. I would not expect two April 26 drafts to be created, but the review agent found both. Every one of those problems was invisible until the system ran.
What that means in practice: you build the system, you run it, you watch it carefully, and you write down every problem in a form the system can read and act on. The investment is not in building the perfect first version. It is in building the feedback mechanism that lets you fix the imperfect version efficiently. For me now, I deliver it feedback live when I see it. For example, I had already noted to Claude that the format was changing.
The briefing system I run today is on its fourth or fifth iteration. The standing rules document has grown from six items to twenty. The recurring review exists because I added it after losing track of patterns across issues. The skill update sitting in my outputs folder right now (the one that adds the source-institution deduplication logic and an eight-item pre-save format self-check) exists because the May 1 review surfaced three problems I had not yet addressed systematically.
The system does not improve itself. I improve it. The agent runs the rules. I write the rules.
One Last Thing
The report filed itself to my folder on May 1. I opened it in my next session, read the findings, and decided what to do. The pending skill update has now been made canonical with a direct update to the underlying skill and feedback file.
A system that audits itself and files the report is genuinely useful. A system that acts on its own findings without me is a different and worse thing. The review identifies problems and puts them in front of me. I still have to decide which ones matter and what to do about them. That is not a gap in the automation. It is the point.
If you’re building something similar, I’d genuinely like to hear what’s working and what isn’t: christina@workforcerewired.co
The Prompt Log is a recurring feature of Workforce Rewired. Published when there’s something honest to say about the process.