

Nobody Can See the Work Anymore
AI broke the thing managers were quietly relying on: the ability to look at output and infer effort, skill, and judgment


TL;DR: Eighty-nine percent of engineering leaders say AI made their teams more productive. The same leaders admit their metrics miss tech debt, validation time, and burnout, and only 6 percent feel equipped to fix that. The gap between those numbers is where management is quietly breaking. When the work moves inside a model the manager can’t see, output stops telling you who is good at their job. Most companies are responding by buying more surveillance. The ones that pull ahead will rebuild what they measure.
A manager has always done one private calculation, fast and mostly unconscious: look at what someone produced, and back out how good they are. Clean code, a tight memo, a deck that lands. The output was a proxy for the person. It told you who to promote, who to coach, who to trust with the hard thing next quarter.
That proxy just stopped working, and almost no one has said so out loud.
When a junior analyst hands you a flawless competitive brief, you no longer know what you’re looking at. Maybe she structured the analysis, found the non-obvious angle, and used the model to format it. Maybe she typed three sentences into a prompt and shipped what came back without reading it closely. The brief looks identical either way. The skill behind it is the difference between someone you fast-track and someone you’ve just learned you can’t rely on. The artifact stopped carrying that information.
This is the management problem of the decade, and it is not the one getting attention. The conversation is stuck on whether AI makes people more productive. That question is nearly settled and mostly boring. The harder question is what happens to evaluation, development, and trust when output decouples from the person who produced it.
The numbers don’t add up, and the people reporting them know it
Harness surveyed 700 engineers and managers across five countries for its State of Engineering Excellence 2026 report. The headline looks like a clean win: 89 percent of engineering leaders say developer productivity improved since they deployed AI. Then the same report turns the lights on. Eighty-one percent of those leaders say code review time went up after deploying AI, in many cases sharply. Developers estimate that roughly a third of their day now goes to AI-related work that shows up in no metric at all: reading code written in a style nobody recognizes, tracking down the subtle bug the model introduced, supervising ten agents running in parallel.
So output went up and invisible labor went up at the same time. Both are true. The dashboard only shows you the first one.
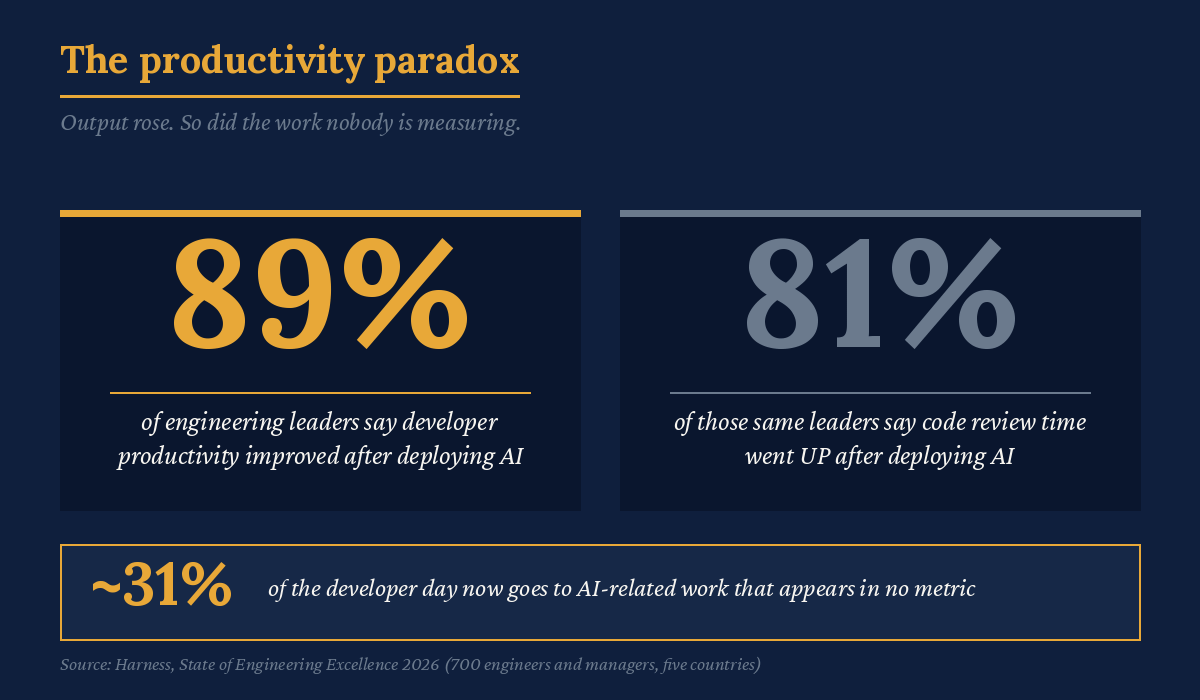
The most revealing finding in the Harness data is a contradiction sitting inside the same population. Eighty-nine percent of leaders say their current metrics accurately reflect AI’s impact. Ninety-four percent say those same metrics miss the factors that matter most: tech debt, validation time, developer burnout. Both groups are largely the same people. They are confident in a measurement system they simultaneously describe as blind. Only 6 percent believe they’re equipped to close the gap.
That is not a calibration error you fix with a better chart. High confidence in a system you know is incomplete is a coping mechanism. When a familiar metric is the only thing you have, you keep trusting it past the point where it tells you the truth, because the alternative is admitting you can’t see the work anymore.
Output was always a proxy for performance
Spend twenty years in talent strategy and you learn what performance measurement actually does. It runs on inference. A manager used tickets closed, lines shipped, decks delivered, deals booked as readable signs of the things that matter and are difficult to measure: judgment, initiative, reliability, the capacity to handle ambiguity. The output was legible on its face. The qualities underneath stayed hidden. So a manager read the obvious thing and inferred the rest.
AI severs the link between the two.
Now heavy output can mean a person is creative and fast, or it can mean they are dependent, indecisive, and outsourcing thinking they haven’t done. Light AI use can mean someone is resistant and falling behind, or it can mean they are skilled enough that they don’t need the crutch for routine work.
The Harness and Worklytics analyses both land on the same uncomfortable point: usage data is nearly uninterpretable as a performance signal, because the same number can mean opposite things about two different people.

This is why the self-reported gains deserve a hard look. METR surveyed 349 technical workers in early 2026 and found a median self-reported 1.4 to 2x improvement in the value of their work from AI tools. Striking, until you read METR’s own caution: in a 2025 controlled study, experienced developers believed AI sped them up by 20 percent while it actually slowed them down by 19 percent. People are confidently wrong about their own productivity. If the workers can’t accurately read their own output, the manager reading it secondhand through a dashboard has no chance.
The reflex is surveillance; it makes the data worse
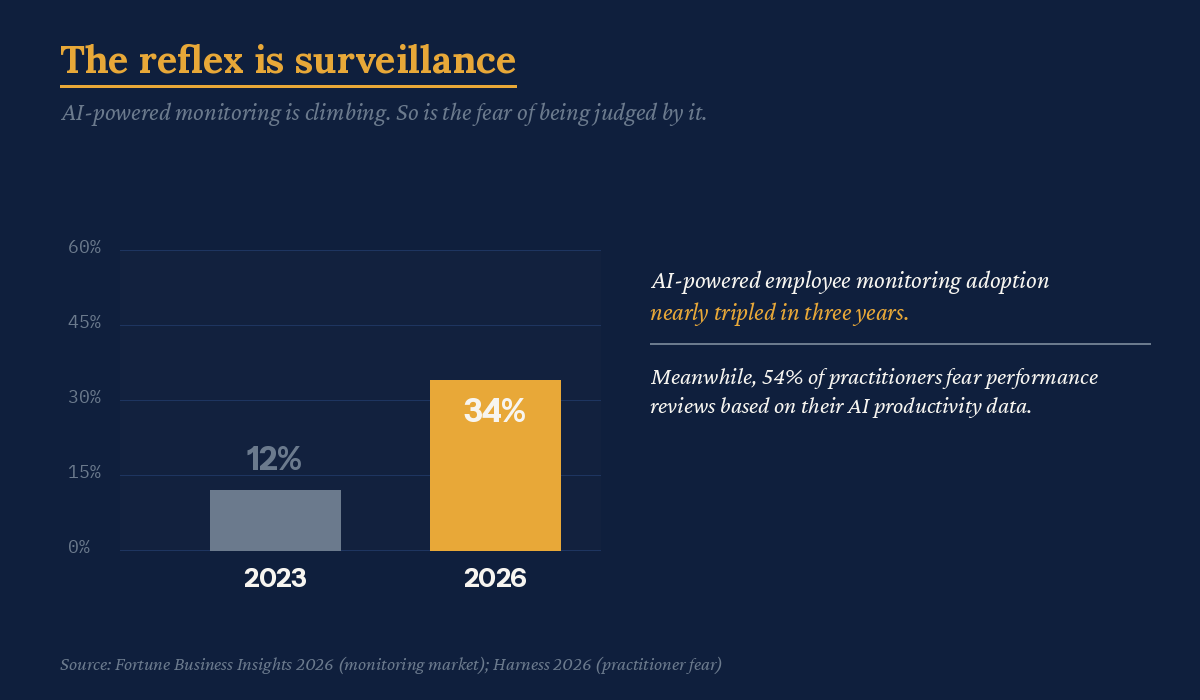
Faced with work they can no longer see, companies are reaching for the oldest tool in the drawer: watch harder. Roughly 78 percent of employers now run some form of employee monitoring, up from about 60 percent before the pandemic. AI-powered monitoring specifically jumped from 12 percent of enterprises in 2023 to 34 percent in 2026. CNBC reports that almost every Fortune 500 company now tracks AI usage at the group, role, or individual level, mostly because token cost became a budget line, not because anyone proved the tracking reveals who is good at their job.
Here is the problem with answering an inference crisis by counting keystrokes. The thing you can measure cheaply, activity, is exactly the thing AI made meaningless. You end up with a high-resolution picture of motion and no picture of value. Worse, the measured know they’re being measured. Harness found that 54 percent of practitioners fear individual performance evaluation based on AI productivity data, while managers are nearly four times more likely to report no concerns at all.
When measurement feels like surveillance, you don’t get accurate data. You get people optimizing for the dashboard. The analyst learns to generate the activity the system rewards instead of doing the work the business needs. You have spent money to make the signal dirtier.
What actually rebuilds the signal
The companies that come out ahead will stop trying to see the work and start measuring the thing output used to stand in for. That means moving evaluation away from artifacts and toward judgment, which is harder, slower, and one of the few things left that AI hasn’t commoditized.
A few moves separate the organizations rebuilding the signal from the ones buying more cameras:
Measure shipped value. Harness found most organizations can say how much AI code was accepted, but few can say how much reached production. Acceptance is vanity. Production is the business. Apply the same test everywhere: count what survived contact with reality, and treat raw output volume as noise.
Evaluate the editing. When the model writes the first draft, the human contribution is the judgment applied to it: what got cut, what got caught, what got challenged. Review those decisions. Ask someone to walk you through what the AI got wrong and how they knew.
Separate improvement data from performance data, and say so. Developers in the Harness study asked for one thing plainly: keep the usage metrics out of the performance review, be transparent about what’s tracked, and involve them in defining it. None of that is technically hard. It requires the discipline to leave the easiest number in the room alone.
Promote on problems posed. The work AI can’t touch is deciding which problem is worth solving. That has always been the senior skill. It is still the durable one. Watch who reframes the question, and pay less attention to who clears the queue fastest.
We can no longer build talent strategies on the assumption that output is a reliable read on the person behind it.
That assumption is now fully faulty, and pretending otherwise is how good people get mismanaged and mediocre ones get promoted on borrowed competence. The managers who notice first, and rebuild what they’re actually measuring, will spend the next five years making better calls than the competitors still staring at a dashboard that stopped telling the truth.
Here’s How You Take Action
If you manage people: Pick one direct report this week and stop reviewing their output. Instead, ask them to walk you through one decision the AI got wrong and how they caught it. That conversation tells you more about their judgment than a quarter of clean deliverables.
If you set measurement strategy: Audit your dashboards for the Harness gap. List what you measure, then list what actually drives value, tech debt, validation, the work that didn’t ship. If the two lists don’t match, your confidence in the first list is the problem.
If you’re being measured: Don’t perform for the dashboard. Build a record of the judgment calls you make, the problems you chose, the model output you rejected and why. When output stops proving skill, the people who can show their reasoning win.
For everyone: Ask the uncomfortable question in your next leadership meeting. When this team’s output looks identical whether the person is excellent or just well-prompted, how are we telling the difference? If the room goes quiet, you’ve found the work nobody is doing yet.
Christina Lexa writes Workforce Rewired, on the intersection of workforce transformation, AI, and global talent.
The views expressed here are my own and do not represent the position of my employer or any organization I am affiliated with.